
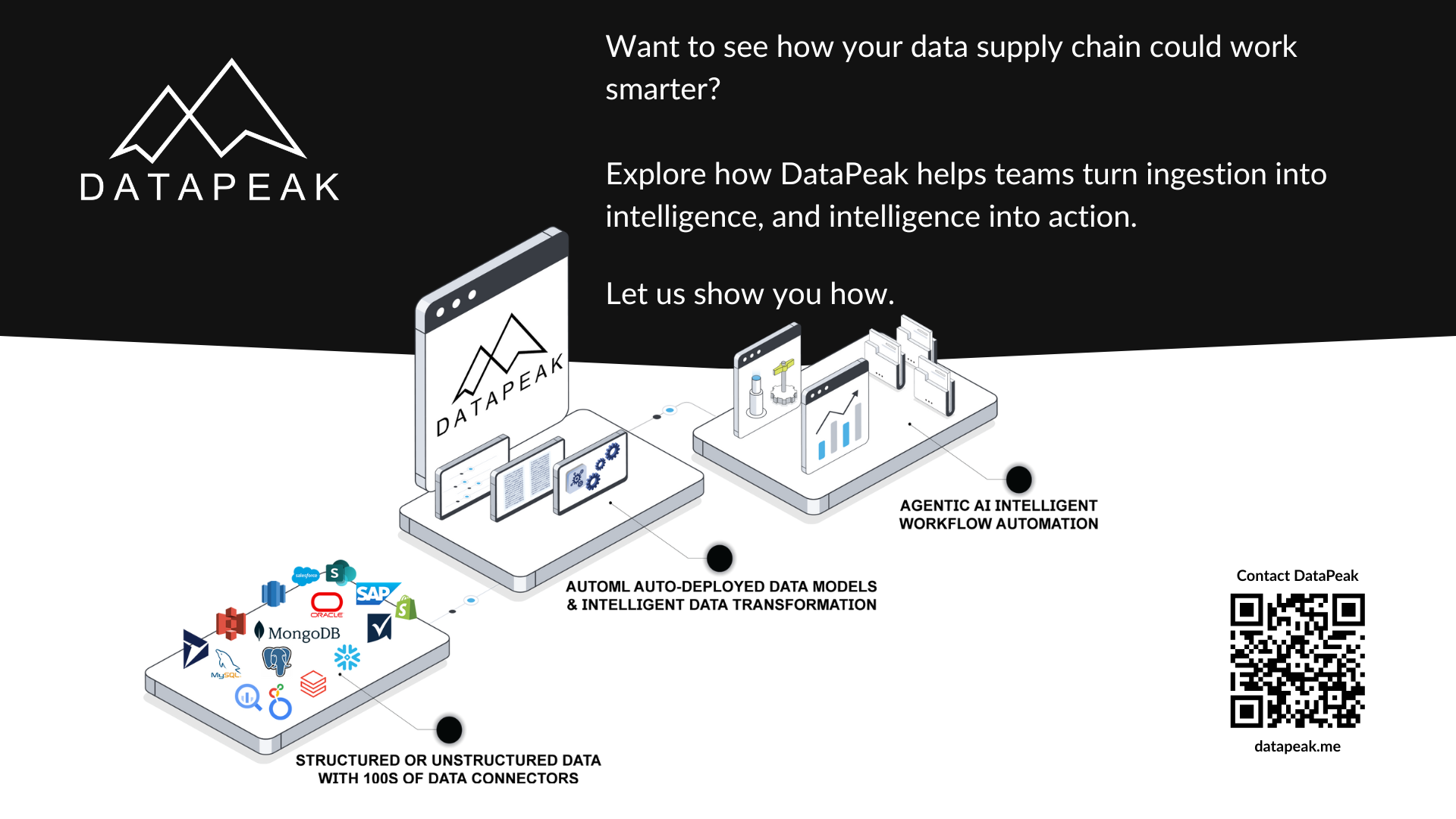
The New Data Supply Chain: From Ingestion to Intelligence
The Disconnect Between Data and Decisions
Most organizations have pipelines that move data. They ingest, transform, and deliver it to dashboards or reports.
But too often, that’s where the process stops. Data gets collected, but it doesn’t drive action. Insights sit idle. Decisions lag. Automation stalls.
The modern data supply chain solves this by connecting every step. It moves from raw input to real-world impact.

Ingestion: Where Intelligence Begins
Data ingestion isn’t just about pulling information from a source. It’s the moment where context, quality, and velocity begin.
Retail → Ingest point-of-sale data to track inventory in real time
Healthcare → Pull patient records to monitor treatment outcomes
Public Sector → Collect service usage data to forecast demand
In the old model, ingestion was a technical chore. Teams built custom scripts, waited for batch jobs, and dealt with delays every time a source changed. The process was brittle, slow, and disconnected from business goals.
In a modern supply chain, ingestion is dynamic. Data arrives clean, structured, and ready to act, without manual intervention.
ETL That Adapts to Change
Traditional ETL is fragile. Every schema shift or data anomaly creates friction.
Pipelines break. Reports stall. And teams scramble to fix transformations that should have been automatic.
Modern pipelines use AI to stay ahead:
Automate transformations with no-code logic
Monitor pipeline health in real time
Trigger model retraining when new patterns emerge
Instead of reacting to change, smart ETL anticipates it. It learns from the data itself and adjusts without slowing down the flow.
This isn’t just about moving data. It’s about building systems that stay aligned with reality.
Why Most Pipelines Fall Short
Even with ingestion and transformation in place, many pipelines fail to deliver intelligence. Common blockers include:
Siloed tools that don’t connect to models or workflows
Manual steps that delay insights
Lack of feedback loops to improve performance over time
Smart pipelines only work when they’re connected end to end. They must move from source to action.
DataPeak’s Edge: AI Pipelines That Learn and Act
With DataPeak, the data supply chain becomes a strategic system. It helps teams respond to change in real time, scale intelligence without scaling headcount, and build systems that learn from every cycle.
Here’s how it works:
No-code orchestration lets teams build full pipelines without writing scripts
Agentic AI workflows turn pipeline outputs into automated decisions
Outcome tracking closes the loop so models retrain based on real-world results
Governance tools ensure every step is secure, auditable, and aligned with business goals
The result is a pipeline that doesn’t just deliver data. It delivers outcomes.
Example in Practice
Imagine a public sector operations lead:
They ingest service usage data across departments. The system detects a spike in demand for housing support in one region. It automatically updates forecasts, reroutes budget allocations, and alerts leadership.
No delays. No manual reports. Just clean data, smart models, and instant action.
That’s the power of a connected supply chain. One that doesn’t just move data. It moves the business.
Beyond Movement: Building Momentum
Ingestion is just the beginning. Transformation is just the middle. The real value comes when data drives decisions. It must happen automatically, intelligently, and at scale.
DataPeak makes that possible. Because the future of data is not just about movement. It’s about momentum.
Keyword Profile: DataPeak Data Management, Data Ingestion, ETL Automation, AI Data Pipelines